Choosing parameters for Lora
To train with QLoRA, one needs to pick a lot of parameters as seen in Training a model and Preparing a model for PEFT.
- the Rank
The rank is the size of matrix used for the fine-tuning.
config = LoraConfig(
r=8, # The rank
...
)
model = get_peft_model(model, config)
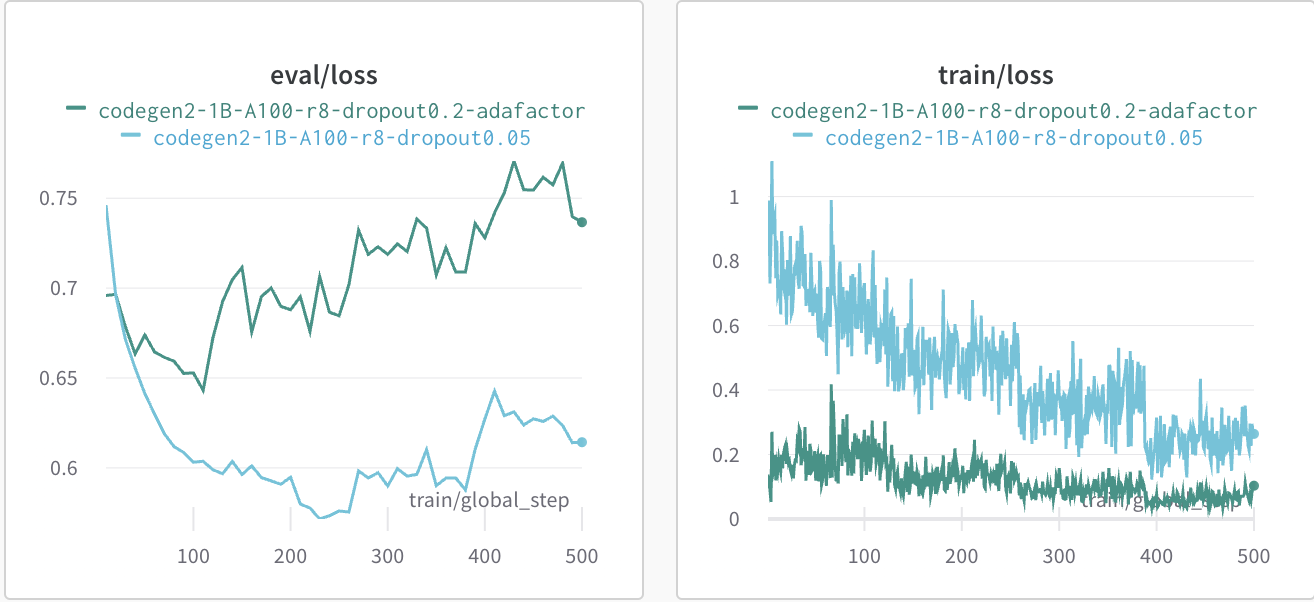
The choice of is crucial as it represents the number of parameters the model will be trained with. In my experiments, influences the training speed as well as the risk of overfitting.
This is a comparison of two run where I train a test generation model with and :
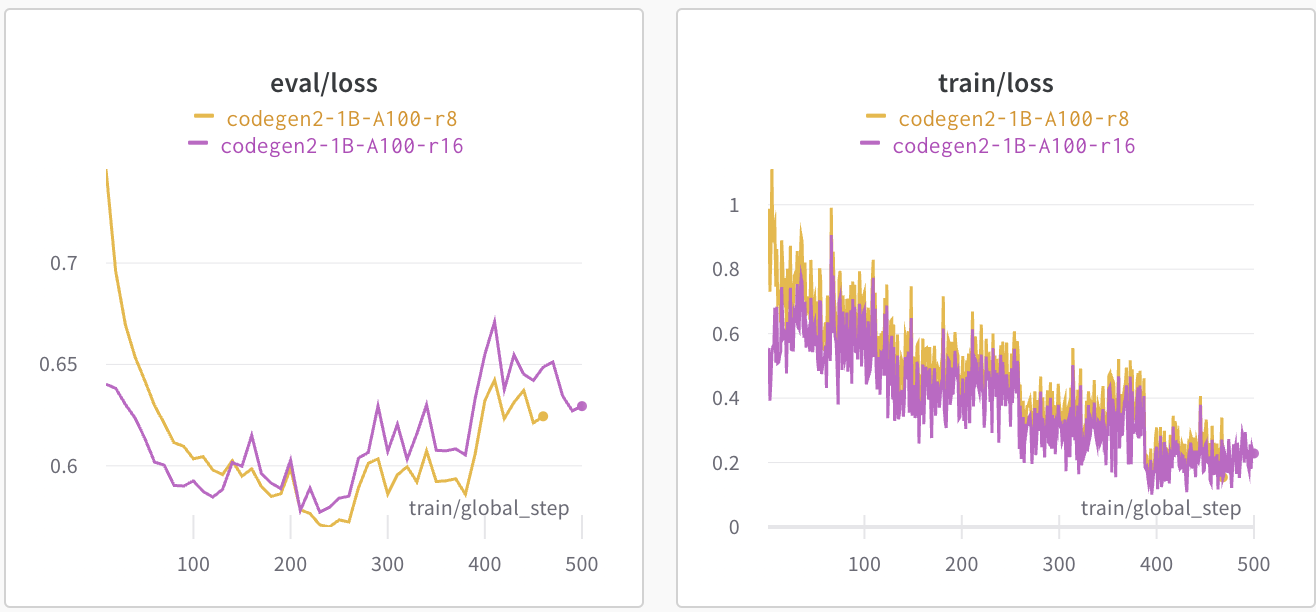
What matters is the eval/loss as it is how well the model is doing on the
testing data as the number of steps increase. We see that the smaller
performs better.
The choice of depends on the amount of data available. 8 seems optimal for about 700 data points that contain about 1000 tokens each.
This parameter increases linearly the number of trained parameters and thus the memory consumption and execution speed.
lora_dropout
lora_dropout represents how often do we set matrix parameters to zero (at
random). It is supposed to reduce the likelihood of overfitting.
config = LoraConfig(
lora_dropout=0.05, # dropout
...
)
model = get_peft_model(model, config)
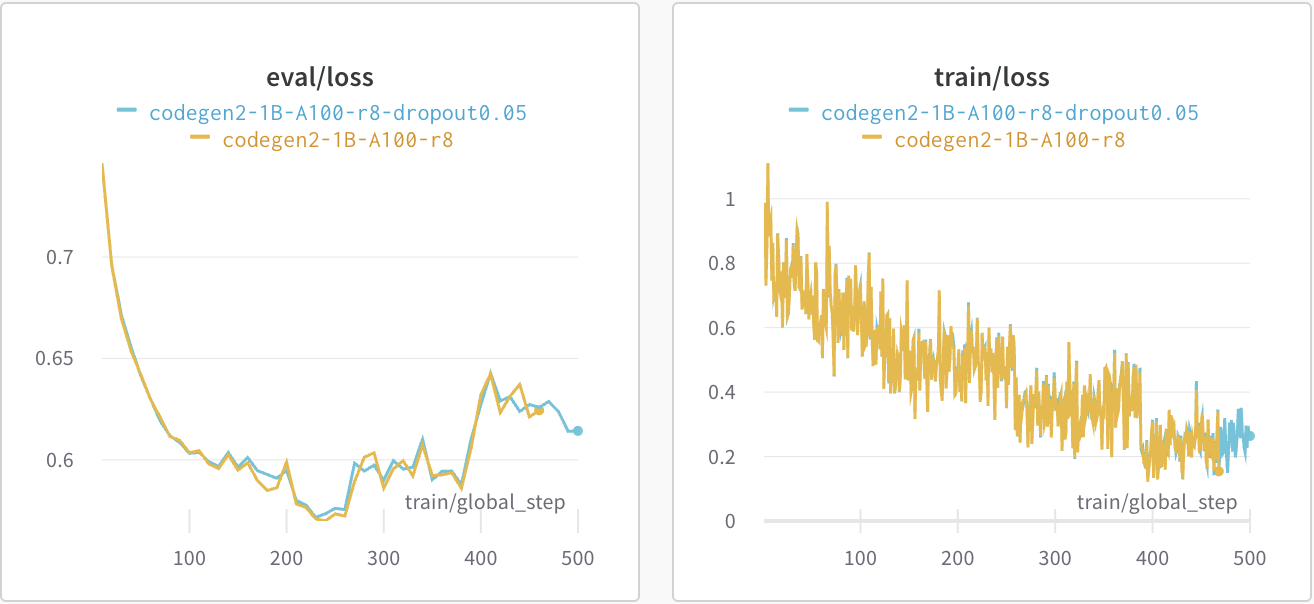
The lora_dropout parameter does not seem to play a big role in training. The
two previous run were made with a dropout of 0.01. This is a comparison of a
run with a dropout of 0.05 with one at 0.01. As we can see, the
eval/loss is almost the same.
This parameter has no impact on training speed or memory usage.
Optimiser
The optimiser is the algorithm that handles the speed of the training process.
args = transformers.TrainingArguments(
optim="adafactor" # the optimiser
)
trainer = transformers.Trainer(
tokenizer=tokenizer,
model=model,
train_dataset=data,
args=args,
data_collator=data_collator,
)
I compared mainly adam and adafactor as Adam is the most commonly used
optimizer and adafactor is an optimiser known to do well while using much less
memory.
Adam uses 8 bytes per parameter of the model for optimisation while Adafactor uses only 4 bytes
We see that Adam's reputation as the go-to optimiser is well deserved.