Beam search
When picking the next token, instead of considering the probability of the next token alone, one can ask, what is the joint probability of picking one token and another afterwards.
This can we seen in this diagram:
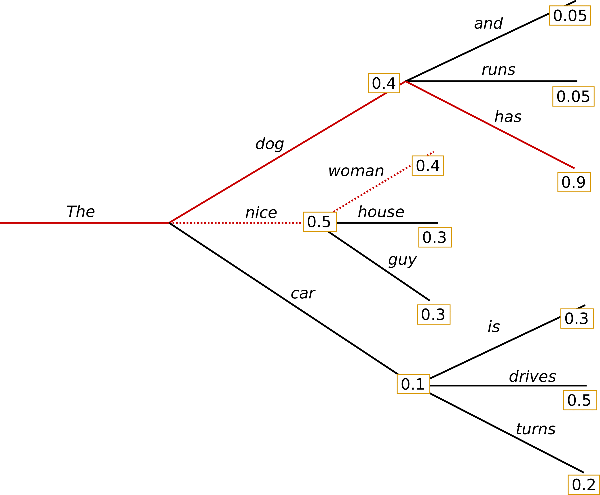
Your prompt is "The" When the model needs to decide what to generate, it decides between "nice" and "dog". While "nice" has a 0.5 probability of being the next token, "the dog has" has a 0.4 * 0.9 probability of being generated which is higher than any of the pairs of tokens that come after "nice", so the model will generate "the dog has" and not "the nice woman".
We call this process of looking forward in the probability space as "beam_search", with the length of the look-ahead windows as the number of beams. In the diagram, we perform a beam search of length 2.
This gives the model forward looking abilities and leads to better text being generated. This can be combined with "top_k" sampling and other techniques to produce quality text as explained in Transformer decoding methods.