Optimiser
As explained in Train a neural network, the formula for updating the weights of a neural network is: is called the learning rate and is how quickly we move through the weight space to minimise the loss. changes during the training process and is picked by an algorithm called the optimiser.
There are multiple optimiser algorithm, including
SGD
decreases with a steady rate and tends to zero as the number of steps increases, for example
Adam
depends on the strength of the last update using the following
equation:
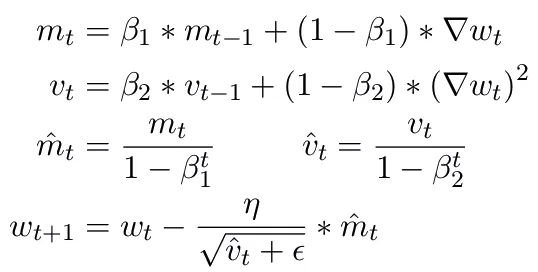 is the new weight, is the base learning rate and the
are fixed hyper-parameters choosen at the start of the training process based on
trial and error and results from other papers.
is the new weight, is the base learning rate and the
are fixed hyper-parameters choosen at the start of the training process based on
trial and error and results from other papers.
The values: are known to work well.